
Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation
We introduce a novel method for robust and accurate 3D object pose estimation from single color images under large occlusions. Following recent approaches, we first predict the 2D projections of 3D points related to the target object and then compute the 3D pose from these correspondences using a geometric method. Unfortunately, as our experiments show, predicting these 2D projections using a regular CNN or a Convolutional Pose Machine is very sensitive to partial occlusions, even when these methods are trained with partially occluded examples. Our solution is to predict heatmaps from multiple small patches independently and to accumulate the results to obtain accurate and robust predictions. Training then becomes challenging because patches with similar appearances but different positions on the object correspond to different heatmaps. However, we provide a simple yet effective solution to deal with such ambiguities. We show that our approach outperforms existing methods on two challenging datasets: The Occluded LineMOD dataset, and the YCB-Video dataset, both exhibiting cluttered scenes with highly occluded objects.
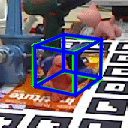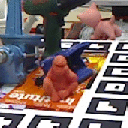
Our method can predict the 3D pose of objects even under heavy occlusions from color images. Samples are objects from the Occluded LineMOD dataset. The green bounding boxes correspond to the ground truth poses, the blue bounding boxes to our estimated poses.
| Cat | Duck | Can |
 |  |  |
| Holepuncher | Driller | Glue |
 |  |  |
This work was supported by the Christian Doppler Laboratory for Semantic 3D Computer Vision, funded in part by Qualcomm Inc.

Material
Results: The 3D pose is represented as pose matrix [R|t] and stored in a plain text file. Each file corresponds to one frame where the file name corresponds to the frame name. Frames where the object is not present are not exported. Note, that there are slight differences compared to the results in the paper, since PnP with RANSAC introduces randomness in the evaluation.