
Feature Mapping
| with Feature Mapping: |  | 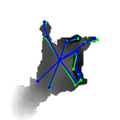 |
|---|---|---|
| w/o Feature Mapping: |  | 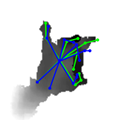 |
About Feature Mapping
Feature Mapping is a simple and efficient method for exploiting synthetic images when training a Deep Network to predict a 3D pose from an image. The ability of using synthetic images for training a Deep Network is extremely valuable as it is easy to create a virtually infinite training set made of such images, while capturing and annotating real images can be very cumbersome.
This work is funded by This work was supported by the Christian Doppler Laboratory for Semantic 3D Computer Vision, funded in part by Qualcomm Inc.

Technical Description
Given a real image of the target object, we first compute the features for the image, map them to the feature space of synthetic images, and finally use the resulting features as input to another network which predicts the 3D pose. Since this network can be trained very effectively by using synthetic images, it performs very well in practice, and inference is faster and more accurate than with an exemplar-based approach. We demonstrate our approach on the LINEMOD dataset for 3D object pose estimation from color images. We show that it allows us to outperform the state-of-the-art on the LINEMOD dataset.
| Metric | Brachmann et al. | BB8 | SSD-6D | Ours |
|---|---|---|---|---|
| 2D Projection | 73.7 | 91.8 | - | 95.4 |
| 6D Pose | 50.2 | 70.1 | 76.6 | 78.7 |
| 5cm 5deg | 40.6 | 73.3 | - | 80.1 |
| Method | Average 3D error |
|---|---|
| Neverova et al. | 14.9mm |
| Crossing Nets | 15.5mm |
| Lie-X | 14.5mm |
| REN | 13.4mm |
| DeepPrior++ | 12.3mm |
| Feedback | 16.2mm |
| Hand3D | 17.6mm |
| DISCO | 20.7mm |
| DeepModel | 16.9mm |
| Synthetic only | 21.1mm |
| Ours | 7.4mm |
Material
Our results: Each line is the estimated hand pose of a frame. The pose is parametrized by the locations of the joints in (u, v, d) coordinates, ie image coordinates and depth. The coordinates of each joint are stored in sequential order.- NYU dataset of J. Tompson: FeatureMapping_DeepPrior++